# 6. Hash Table(해쉬 테이블)
# 해쉬 테이블이란?
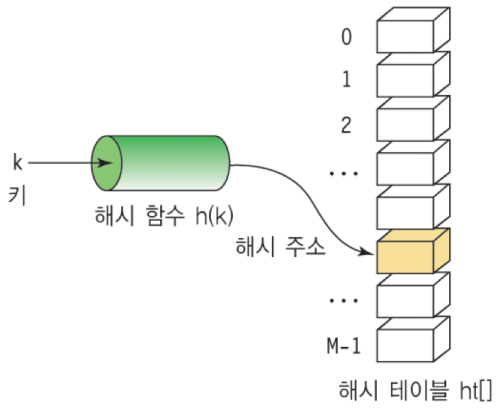
해쉬 테이블(Hash Table): 키(Key)에 데이터(Value)를 저장하는 데이터 구조
- Key를 통해서 데이터를 바로 받아올 수 있으므로 배열에 비해서 속도가 획기적으로 빨라짐
- 파이썬에서는 딕셔너리(Dictionary) 타입이 해쉬 테이블의 예이다. 따라서 파이썬에서는 해쉬를 별도로 구현할 필요가 없다.
- 보통 배열로 미리 Hash Table 사이즈만큼 생성 후에 사용한다.(공간을 늘려서 추가적인 자료구조의 생성을 줄인다.)
- 해쉬를 바탕으로 만들어진 기술은 블록체인(Block Chain)이 있다.
# 알아둘 용어
- 해쉬(Hash): 임의의 값을 고정 길이로 변환하는 것
- 해쉬 테이블(Hash Table): Key 값을 통해 데이터에 직접 접근이 가능한 데이터 구조
- 해싱 함수(Hashing Function): Key에 대해서 산술 연산을 이용해 데이터의 위치를 찾는 함수
- 해쉬 값(Hash Value) or 해쉬 주소(Hash Address): Key를 해싱 함수로 연산해서 해쉬 값을 알아내고, 이를 기반으로 해쉬 테이블에서 해당 Key를 통해 찾아낸 데이터 위치
- 슬롯(Slot): 한 개의 데이터를 저장할 수 있는 공간
저장할 데이터에 대해서 Key를 추출할 수 있는 별도 함수도 존재할 수 있다.
# 간단한 해쉬 예시
# Hash Table
hash_table = [0 for i in range(10)]
# [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
# Hash Function
# 다양한 해쉬함수 고안 기법이 있다. 여기서는 가장 간단한 Division법을 이용한다.
# 나눗셈을 통해서 고정 길이를 가지게 하는 것이다.
def hash_func(key):
return key % 6
# Save Value in Hash Table
def storage_data(data, value):
key = ord(data[0])
hash_address = hash_func(key)
hash_table[hash_address] = value
storage_data('Ludi', '브리엄 여자친구')
storage_data('Brium', '루디 남자친구')
# Get Data
def get_data(data):
key = ord(data[0])
hash_address = hash_func(key)
return hash_table[hash_address]
get_data('Ludi')
# 출력: '브리엄 여자친구'
# 해쉬 테이블의 장단점
- 장점
- 데이터 저장/읽기 속도가 빠르다.
- 검색 속도가 빠르다.
- Key에 대한 중복 데이터가 있는지 확인이 쉽다.
- 당점
- 일반적으로 저장공간이 좀 더 많이 필요하다.
- 여러 키에 해당하는 주소가 동일할 경우, 충돌을 해결하기 위한 별도의 자료구조가 필요하다.
# 해쉬 테이블의 주요 용도
- 검색이 많이 필요한 경우(검색 속도가 빠르기 때문)
- 저장, 삭제, 읽기가 빈번한 경우(저장/읽기 속도가 빠르기 때문)
- 캐쉬를 구현하는 경우(중복확인이 쉬운 장점이 있기 때문)
# 프로그래밍 연습1
연습1: List 변수를 활용해서 Hash Table 구현하기
- 해쉬함수: key % 8
- 해쉬 키 생성: hash(data) 파이썬 내장 함수 사용
hash함수는 파이썬 내장 함수로서 data에 대한 해쉬를 임의의 값으로 생성하는 함수이다.
hash_table = [0 for i in range(8)]
def get_key(data):
return hash(data)
def hash_func(key):
return key % 8
def save_data(data, value):
key = hash_func(get_key(data))
hash_table[key] = value
def read_data(data):
key = hash_func(get_key(data))
return hash_table[key]
save_data('Ludy', '브리엄 여자친구')
sava_data('Brium', '루디 남자친구')
read_data('Ludi')
# 출력: '브리엄 여자친구'
hash_table
# 출력: ['브리엄 여자친구', 0, '루디 남자친구', 0, 0, 0, 0, 0]
# 충돌(Collision) 해결 알고리즘
해쉬 테이블의 가장 큰 문제는 충돌(Collision)이다. 이 문제를 Collision(충돌) 또는 해쉬 충돌(Hash Collision)이라고 부른다.
충돌을 해결하는 기법에는 Chaining, Linear Probing이 있다.
# Chaining 기법
- Open Hashing(개방 해슁) 기법 중 하나이다.
- 해쉬 테이블 저장공간 외의 공간을 활용하는 기법이다.
- 충돌이 일어나면, 링크드 리스트라는 자료 구조를 사용해서 링크드리스트로 데이터를 추가로 뒤에 연결시켜서 저장하는 기법이다.
# 프로그래밍 연습2
연습1의 해쉬 테이블 코드에 Chaining 기법으로 충돌해결 코드를 추가해보기
hash_table = [0 for i in range(8)]
def get_key(data):
return hash(data)
def hash_func(key):
return key % 8
def save_data(data, value):
index_key = get_key(data)
key = hash_func(index_key)
# 해쉬 테이블에 값이 존재한다면,
if hash_table[key] != 0:
for index in range(len(hash_table[key])):
if hash_table[key][index][0] == index_key:
hash_table[key][index][1] = value
return
hash_table[key].append([index_key, value])
else:
hash_table[key] = [[index_key, value]]
def read_data(data):
index_key = get_key(data)
key = hash_func(index_key)
if hash_table[key] != 0:
for index in range(len(hash_table[key])):
if hash_table[key][index][0] == index_key:
return hash_table[key][index][1]
return None
else:
return None
# 아래의 'Ludy', 'Brium' 데이터가 같은 key를 갖는다고 가정한다.
save_data('Ludy', '브리엄 여자친구')
save_data('Brium', '루디 남자친구')
print(hash_table)
# 아래와 같이 같은 키 값을 가진다면 hash를 통해 고정 길이로 변환하기 전의 index_key 값과 value를 리스트 형태로 저장했다.
# 링크드 리스트로 구현하기에는 코드의 길이가 길어지기 때문에 이런식으로 구현했다.
# 출력예시: [0, 0, 0, 0, [[775514214, '브리엄 여자친구'],[876414254, '루디 남자친구']] 0, 0, 0]
# Linear Probing 기법
- Close Hashing(폐쇄 해슁) 기법 중 하나이다.
- 해쉬 테이블 저장공간 안에서 충돌문제를 해결하는 기법
- 충돌이 일어나면, 해당 Hash address의 다음 address부터 맨 처음 나오는 빈 공간에 저장하는 기법
- 저장 공간 활용도를 높이기 위한 기법
# 프로그래밍 연습 3
연습1의 해쉬 테이블 코드에 Linear Probling 기법으로 충돌해결 코드를 추가해보기
- 해쉬 함수: key % 8
- 해쉬 키 생성: hash(data)
hash_table = [0 for i in range(8)]
def get_key(data):
return hash(data)
def hash_function(key):
return key % 8
def save_data(data, value):
index_key = get_key(data)
hash_address = hash_function(index_key)
if hash_table[hash_address] == 0:
hash_table[hash_address] = [index_key, value]
else:
for index in range(hash_address, len(hash_table)):
if hash_table[index] == 0:
hash_table[index] = [index_key, value]
return
elif hash_table[index][0] == index_key:
hash_table[index][1] = value
return
def read_data(data):
index_key = get_key(data)
hash_address = hash_function(index_key)
if hash_table[hash_address] != 0:
for index in range(hash_address, len(hash_table)):
if hash_table[index] == 0:
return None
elif hash_table[index][0] == index_key:
return hash_table[index][1]
else:
return None
# 빈번한 충돌을 개선하는 기법
해쉬 함수 재정의 및 해쉬 테이블 저장 공간을 확대한다.
해쉬 함수와 키 생성 함수
hash() 함수는 실행시마다 값이 달라질 수가 있다.
그에 대응하기 위해서 여러가지 유명한 해쉬 함수가 있는데, 대표적으로 SHA(Secure Hash Algorithm, 안전한 해시 알고리즘)이 있다.
# SHA란?
SHA(Secure Hash Algorithm, 안전한 해시 알고리즘)
- 어떤 데이터도 유일한 고정된 크기의 고정값을 리턴해주므로 해쉬 함수로 유용하게 활용 가능하다.
# SHA-1 사용법
import hashlib
data = "test".encode()
hash_object = hashlib.sha1()
hash_object.update(data)
hex_dig = hash_object.hexdigest()
print(hex_dig)
# a94a8fe5ccb19ba61c4c0873d391e987982fbbd3
# SHA-256 사용법
import hashlib
data = 'test'.encode()
hash_object = hashlib.sha256()
hash_object.update(data)
hex_dig = hash_object.hexdigest()
print(hex_dig)
# 9f86d081884c7d659a2feaa0c55ad015a3bf4f1b2b0b822cd15d6c15b0f00a08
# 프로그래밍 연습4
연습 2의 Chaining 기법을 적용한 해쉬 테이블 코드에 키 생성 함수를 sha256 해쉬 알고리즘을 사용하도록 변경하기
hash_table = [0 for i in range(8)]
def get_key(data):
hash_object = hashlib.sha256()
hash_object.update(data)
hex_dig = hash_object.hexdigest()
return int(hex_dig, 16)
def hash_function(key):
return key % 8
def save_data(data, value):
index_key = get_key(data)
hash_address = hash_function(index_key)
if hash_table[hash_address] == 0:
hash_table[hash_address] = [index_key, value]
else:
for index in range(hash_address, len(hash_table)):
if hash_table[index] == 0:
hash_table[index] = [index_key, value]
return
elif hash_table[index][0] == index_key:
hash_table[index][1] = value
return
def read_data(data):
index_key = get_key(data)
hash_address = hash_function(index_key)
if hash_table[hash_address] != 0:
for index in range(hash_address, len(hash_table)):
if hash_table[index] == 0:
return None
elif hash_table[index][0] == index_key:
return hash_table[index][1]
else:
return None
# 시간 복잡도
- 일반적인 경우(Collision이 없는 경우): O(1)
- 최악의 경우(Collision이 모두 발생하는 경우): O(n)
해쉬 테이블의 경우 Collision을 모두 제외한 일반적인 경우를 기대하고 만들기 때문에 시간 복잡도는 O(1)이라고 말할 수 있다.